
Comment Discord crée des insights à partir de milliards de données ?
Anagram • Publié le 26 November 2021
TraductionsChez Discord, l'équipe des données de la plateforme permet à l'organisation d'analyser, de comprendre, et d'exploiter ces dernières pour aider Discord à créer un espace permettant à chacun de trouver son appartenance. Discord utilise des données pour un certain nombre de raisons : identifier les mauvais acteurs et les communautés nocives ; développer ses perspectives concernant les produits critiques et les décisions stratégiques ; et former et évaluer l'efficacité des modèles d'apprentissage automatique (allez voir notre Politique de Confidentialité pour en savoir plus sur les informations que nous collectionnons et comment nous les utilisons !). Sans analyses régulières et rigoureuses de l'utilisation de notre produit, notre capacité à prendre des décisions sur les stratégies de notre entreprise à cette échelle serait vraiment un manque à gagner.
Les données brutes nous parviennent sous forme d'exportations de banques de données de production et de données de télémétrie (plus de 15 mille milliards d'enregistrements faits jusqu'à aujourd'hui et des milliards d'enregistrements journaliers). Lorsque Discord était une petite entreprise et que les cas d'utilisation des données étaient plus simples, il était quelque peu défendable, voire idéal, de calculer manuellement des ensembles de données utiles selon nos besoins. Aujourd'hui, nous traitons des pétaoctets de données avec 30 000 vCPU dans le cloud. Pour que cela soit utile, les données brutes doivent être traitées, privatisées d'après les politiques de données du gouvernement américain, et ensuite transformées en un schéma complexe de milliers de tables créées par ordinateur dans notre entrepôt de plus de 30 pétaoctets (nous utilisons Google BigQuery).
En ce moment, la partie de l'équipe de données de la plateforme responsable du traitement des données brutes et de leur accessibilité, se compose de 8 personnes, bien plus qu'avant. Étant donné la taille de l'équipe relative au reste de Discord, il était important de construire un système libre-service et aussi automatisé que possible. C'est l'histoire de la façon dont nous avons transformé des pétaoctets de données brutes en un entrepôt de données structurées et un système qui les maintient, appelé en interne Derived.
Prérequis et approche
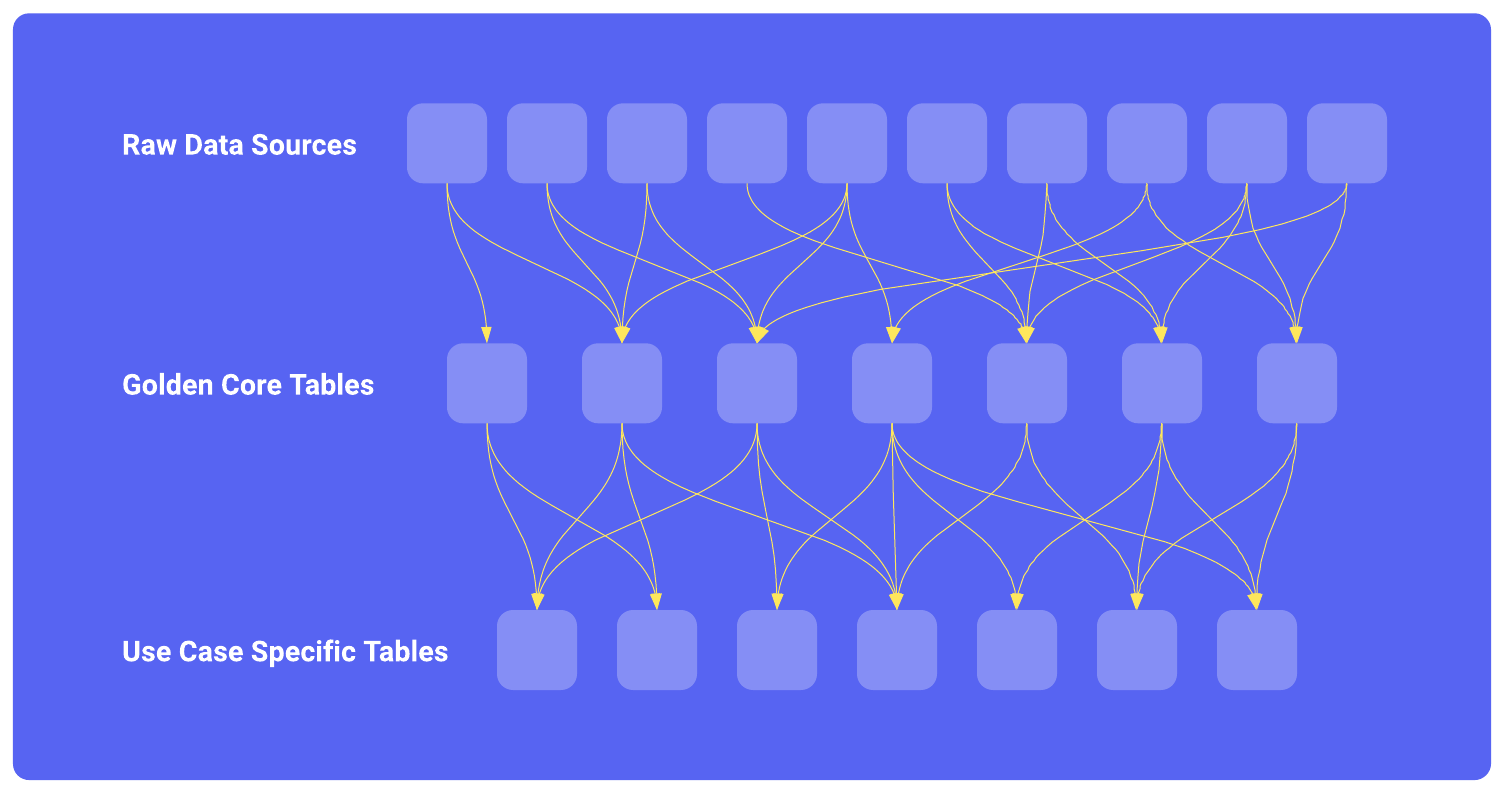
Nous avions besoin d'un système de maintenance d'un graphe acyclique dirigé (DAG) complexe de données précalculées — dans notre cas, cela signifie un DAG de tables dérivées dans notre gros entrepôt BigQuery de données :
- Une table dérivée représente essentiellement une transformation de données qui peuvent avoir des tables prédécesseurs dans le DAG comme dépendance d'entrée : en d'autres termes, une définition de table dérivée peut être une instruction SQL SELECT qui redirige vers des données brutes ou d'autres tables de dérivées.
- En supposant que le DAG circule de haut en bas, on pourrait imaginer qu'en haut du DAG se trouvent les sources de données brutes et les tables de consultation ; au milieu, un ensemble de tables de données de base "dorées" réutilisables (par exemple, les inscriptions quotidiennes normalisées sur toutes les plateformes) ; et vers le bas du DAG, des tables destinés à être utilisés directement dans des analyses, des outils de BI ou des modèles d'apprentissage automatique.
- Le DAG peut contenir des milliers de tables, il doit donc être évolutif.
Bien que le système soit divisé en une série d'étapes livrables, nous voulions que le système final réponde aux exigences suivantes :
- Exécuter les mises à jour des tables dès que de nouvelles données sont disponibles (mais pas plus tôt !).
- Conserver une piste d'audit des mutations de chaque table.
- Inclure des primitives pour alimenter la lignée des données et un catalogue de données.
- Modifications intuitives et en libre-service des tables pour les équipes de parties prenantes comme l'ingénierie, la science des données et l'apprentissage automatique.
- Permettre l'intégration des contrôles d'accès aux données et prendre en charge l'application évolutive des politiques de confidentialité.
- Possibilité d'exporter automatiquement les données dérivées vers les bases de données de production pour les utiliser dans le produit de Discord destiné aux utilisateurs.
- Simplicité et facilité d'utilisation dans le contexte de l'environnement de l'infrastructure de Discord.
Bien que des solutions comme dbt, Airflow et Looker résolvent la plupart des problèmes cités ci-dessus, nous avons finalement souhaité une solution plus adaptée qui pourrait bien s'intégrer dans nos systèmes existants et qui nous donnerait la flexibilité d'étendre les cas d'utilisation au-delà de l'analyse.
Nous utilisions déjà Airflow pour organiser des travaux par lots et traiter des jeux de données plus simples, mais nous avons découvert quelques limitations :
- Écrire les travaux était compliqué car cela demandait aux utilisateurs d'avoir de solides connaissances sur Python, SQL et Airflow. Cela a enfreint notre prérequis sur le fait que les modifications de DAG devaient être automatisées.
- Organiser la planification de requêtes qui dépendaient les unes des autres selon des horaires différents (par exemple, savoir quand mettre à jour une table planifiée chaque semaine et lue à partir d’une table mise à jour mensuellement).
- Savoir exactement où insérer votre table intégrée dans le graphique de dépendance et comprendre son impact sur les autres tables n’était pas simple (par exemple, savoir quand vos tables doivent être remplies parce que les jeux de données précédents appartenant à une autre équipe étaient incomplets, introduisaient des données corrompues ou avaient des modifications de données).
- L'écriture de la logique pour les constructions de données incrémentielles qui ajoutent ou fusionnent des données dans une table existante était sujette aux erreurs et au copier-coller, surtout si l'on tient compte de toutes les conditions potentielles de reconstruction et de remplissage.
En prenant en compte nos prérequis, en ayant observé les points sensibles et en s'inspirant des solutions existantes, nous avons fait les choix de conception suivants :
- Les utilisateurs devront seulement connaître le SQL pour définir des tables dérivées.
- Les utilisateurs n'auront pas besoin de connaître la structure spécifique du DAG : le système déduira le DAG à partir du SQL.
- Tous les éléments devront être présents dans git pour un historique complet des modifications et une recherche facile des configurations de production actuelles.
- Le système intégrera du traitement de données avec nos systèmes existants de privatisation et des politiques gouvernementales sur les données. Nous prenons la vie privée de nos utilisateurs très au sérieux, et il était primordial que tout ce que nous construisions respecte nos stricts contrôles de confidentialité.
- L'historique de métadonnées et l'état actuel de chaque table devra être enregistré en un format accessible pour construire des outils de surveillance, de lignée et de performances.
- Les opérations de réparations de données (quand il y a des données manquantes) devront être simples et assurer la cohérence des données à travers tout l'entrepôt de données.
Version 1 : Le produit minimum viable
Pour le livrable initial, les objectifs prioritaires les plus élevés étaient d'intégrer les transformations de données dans git, de s'assurer que les données étaient cohérentes dans l'entrepôt et de simplifier les opérations de données. Nous avons construit les éléments suivants :
- Les tables dérivées devraient être définies par du SQL en utilisant des fichiers dans un format de modèles de Jinja. Chaque table serait configurée dans son propre fichier et stockée dans git.
- Le framework construirait les dépendances du DAG basées sur les configurations de tables ainsi que l'entrepôt de données, pour tirer parti d'Airflow pour ses travaux organisés, sa visualisation, et sa surveillance.
- Nous construirions un outil de ligne de commandes pour reconstruire précisément et remplir les trous de nos tables.
- Afin de gérer la portée du MVP, nous avons décidé de regrouper les tables par calendrier de mise à jour (par exemple, horaire, quotidien, hebdomadaire ou mensuel) pour éviter une logique complexe de résolution des dépendances. En contrepartie, nous ne pouvions pas facilement mélanger des tables ayant des calendriers de mise à jour différents.
Le comportement de génération de table spécifié à l'aide de l'une des trois stratégies différentes permet de déterminer comment les tables sont construites, incrémentées et remplies :
- Remplacer : remplacer entièrement la table à intervalles réguliers.
- Ajouter : ajouter des données de façon incrémentale à une table à intervalles réguliers.
- Fusionner : fusionner des données arrivantes avec des données existantes basées sur des critères. Cette stratégie est principalement utilisée avec les tables supportant l'analyse de cohorte où nous voulons segmenter sur les attributs des utilisateurs tels que "la première fois qu'un utilisateur a utilisé le chat vocal" ou "la dernière fois qu'un utilisateur a rejoint un serveur communautaire Discord".
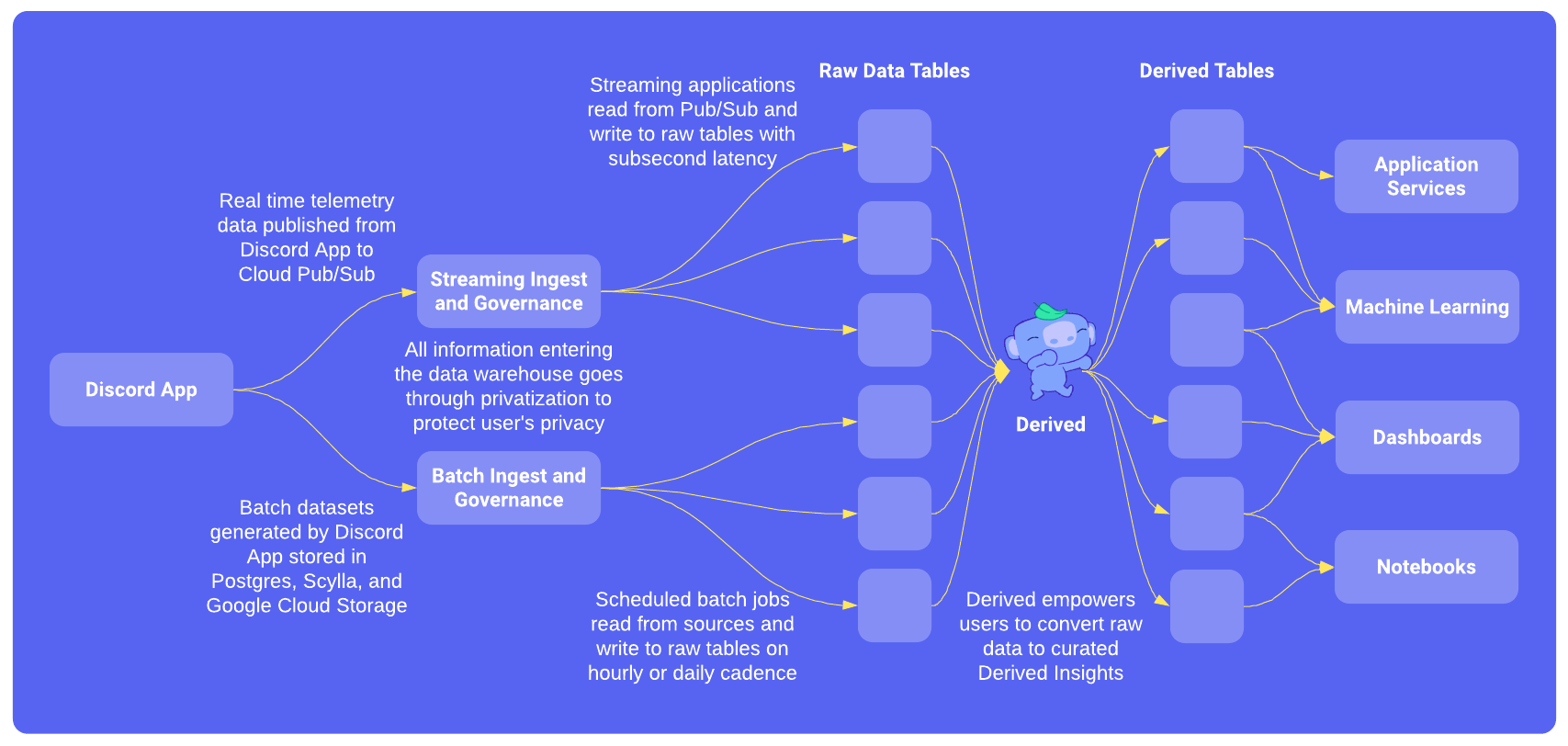
Ainsi, Derived est né et s'intègre dans notre architecture comme illustré ci-dessous :
Version 2 : Ergonomie
Le MVP a prouvé la technologie de construction du DAG, des tables et de gestion des données de l'entrepôt, mais les gens en interne avaient du mal à créer de nouvelles tables dérivées sans l'aide des ingénieurs en données puisque le processus était trop compliqué et obscur. Donc pour la prochaine itération, nous nous sommes concentrés sur la création d'une interface d'utilisateurs plus simple pour facilement créer de nouvelles tables et écrire de la documentation juste à côté de leur code.
Fonctionnalités :
- L'introduction du format YAML afin que les gens puissent se concentrer sur l'écriture du SQL et n'aient qu'à apprendre quelques propriétés pour la fréquence d'exécution de la table et la fenêtre (plage de temps) de données sur laquelle elle doit s'exécuter.
- Activation des dépendances entre les tables avec n’importe quelle combinaison de planification, de fenêtre et de stratégie afin que les utilisateurs n’aient pas besoin de connaître la structure spécifique du DAG et ses dépendances.
- Une limitation que nous avons acceptée pour cette itération était que la table de métadonnées était toujours stockée dans Airflow, et cela nous obligerait à mettre en pause le DAG d'Airflow pour effectuer des opérations de réparation. En outre, la synchronisation de l'état des tables avec la table de métadonnées d'Airflow après la reconstruction était complexe.
Lorsque la définition de la table est fusionnée dans la branche principale, Derived crée la table et la remplit avec toutes les données existantes. Pour chaque exécution ultérieure, il insère une heure de données dans la table existante - une opération de FUSION en termes de BigQuery. En outre, comme vous pouvez le voir ci-dessous, la documentation relative aux définitions des tables et des colonnes vit avec la définition de la table, ce qui minimise la possibilité de dérive entre la fonctionnalité du tableau et la documentation.
columns:
- [emoji_id, INT64, NOT NULL, 'ID of an emoji']
- [timestamp, TIMESTAMP, NOT NULL, 'First time a custom emoji was sent']
- [timestamp_hour, TIMESTAMP, NOT NULL, 'Descriptions are added to database schemas so they appear in the BigQuery UI']
description: 'The table description used in data discovery tooling and generated documentation'
category: 'Category for organizing generated documentation'
strategy: merge # Merge means to incrementally update or insert records into the table based on the merge_keys and merge_mode
merge_keys: [emoji_id] # The table will have at most one record per emoji, if there is no record for the emoji then insert it otherwise ignore new records
merge_mode: keep_oldest # Only record the first time an emoji was sent and ignore all future records
merge_timestamp: timestamp # Determine the first time an emoji was sent based on timestamp in the send_emoji event
schedule: daily # Incrementally update this table once per day
window: daily # Add one day of source data each run
partition_by: timestamp_hour # Partition the BigQuery table by timestamp_hour
cluster_by: [emoji_id] # Sort each partition by emoji_id
timezone: pt # Timestamps are pacific timezone and daily aggregates are pacific timezone days
dataset: emoji_cohorts # BigQuery dataset
sql: |
SELECT
emoji_id,
MIN(timestamp) AS timestamp,
TIMESTAMP_TRUNC(MIN(timestamp), HOUR) AS timestamp_hour
FROM events.send_emoji
WHERE timestamp >= @start_day_utc # Derived injects timestamps based on data availability of predecessor dependencies
AND timestamp < @end_day_utc # start_day_utc and end_day_utc are computed based on incremental, rebuild, and backfill operations
GROUP BY emoji_id
Un autre avantage de l'adoption de cette interface normalisée est qu'elle fournit une couche d'abstraction qui nous permet d'itérer rapidement sur les systèmes sous-jacents à la configuration sans impacter les équipes.
Version 3 : Automatisation
La version 2 a permis à nos équipes de science des données de créer des centaines de tables sans assistance au cours de la première année. Ce succès a entraîné une nouvelle série de problèmes :
- La création de nouvelles tables était simple mais les actualiser demandait de l'aide aux ingénieurs en données : les constructions/reconstructions du DAG n'étaient pas automatisées et devaient être retouchées par des ingénieurs. Bien que ces tâches d'entretien soient relativement simples, elles prennent du temps et sont plus fréquentes à mesure que l'adoption augmente.
- Une seule table avec un bug de SQL bloquait tous les processus de toutes les tables et les bugs devenaient plus fréquents à mesure que l'adoption augmentait : Les suites de tests ne testaient pas de manière exhaustive toutes les combinaisons du SQL généré, ni les dépendances entre les tables. Pire, les bugs ne se manifestaient souvent qu'en cours d'exécution en production, en raison d'hypothèses incorrectes sur les données, et qu'il fallait souvent que les ingénieurs en données remplissent à nouveau les données et réparent les tables.
- Il était difficile d'utiliser les informations de Derived pour alimenter les fonctionnalités des applications, car ****l'entrepôt de données (BigQuery) n'est pas optimisé pour les exigences de latence en millisecondes des services destinés aux utilisateurs.
La version 3 est donc concentrée sur l'amélioration de la fiabilité des déplacements et l'automatisation de la reconstruction/réparation des tables dérivées. Pour accomplir cela, nous nous sommes concentrés sur l'ergonomie, les tests et l'automatisation générale :
Tester :
Nous voulions que les utilisateurs puissent faire des tests tout en développant de nouvelles tables, nous avons donc mis en place ce qui suit :
- Pour du développement local, les gens pourraient utiliser des interfaces à lignes de commande (CLI) pour charger les configurations des tables et valider les dépendances au travers du DAG.
- Depuis le CLI, les utilisateurs peuvent également créer des versions de test de leurs tables sur des données de production fictives pour vérifier les sorties de la table.
- Une fois qu'une requête d'extraction est créée, une intégration continue (CI) déploie toute les nouvelles tables sur un environnement de production fictif afin que les utilisateurs puissent valider les changements opérés avec les vraies données avant de fusionner la demande d'extraction.
Automatisation :
Dans la version 2 de Derived, les métadonnées de la table ont été suivies dans Airflow, ce qui entraîne un certain nombre d'étapes manuelles pendant les opérations de maintenance des données (par exemple, un remblayage nécessite de mettre le DAG en pause, d'éxecuter l'opération, puis de synchroniser l'état réel de la table avec les métadonnées d'Airflow).
Pour automatiser les opérations de données, nous avons déplacé le suivi de l'état des tables hors d'Airflow et dans un journal de métadonnées afin que Derived puisse décider indépendamment quand réparer, reconstruire et ajouter des données aux tables.
Un suivi d'état plus détaillé au niveau de la table débloque également les calculs parallèles afin qu'un processus parent ne se bloque pas lors du séquençage et l'arrangement de plus de 900 tables. Toutes les tables peuvent s'exécuter simultanément et aussi fréquemment que souhaité pour que les aperçus de Derived restent cohérents dans l'entrepôt de données et à jour avec les sources de données. Chaque programme de mise à jour des tables est déployé en tant que son propre "Pod Kubernetes" : lorsqu'un pod démarre, il passe par les étapes suivantes :
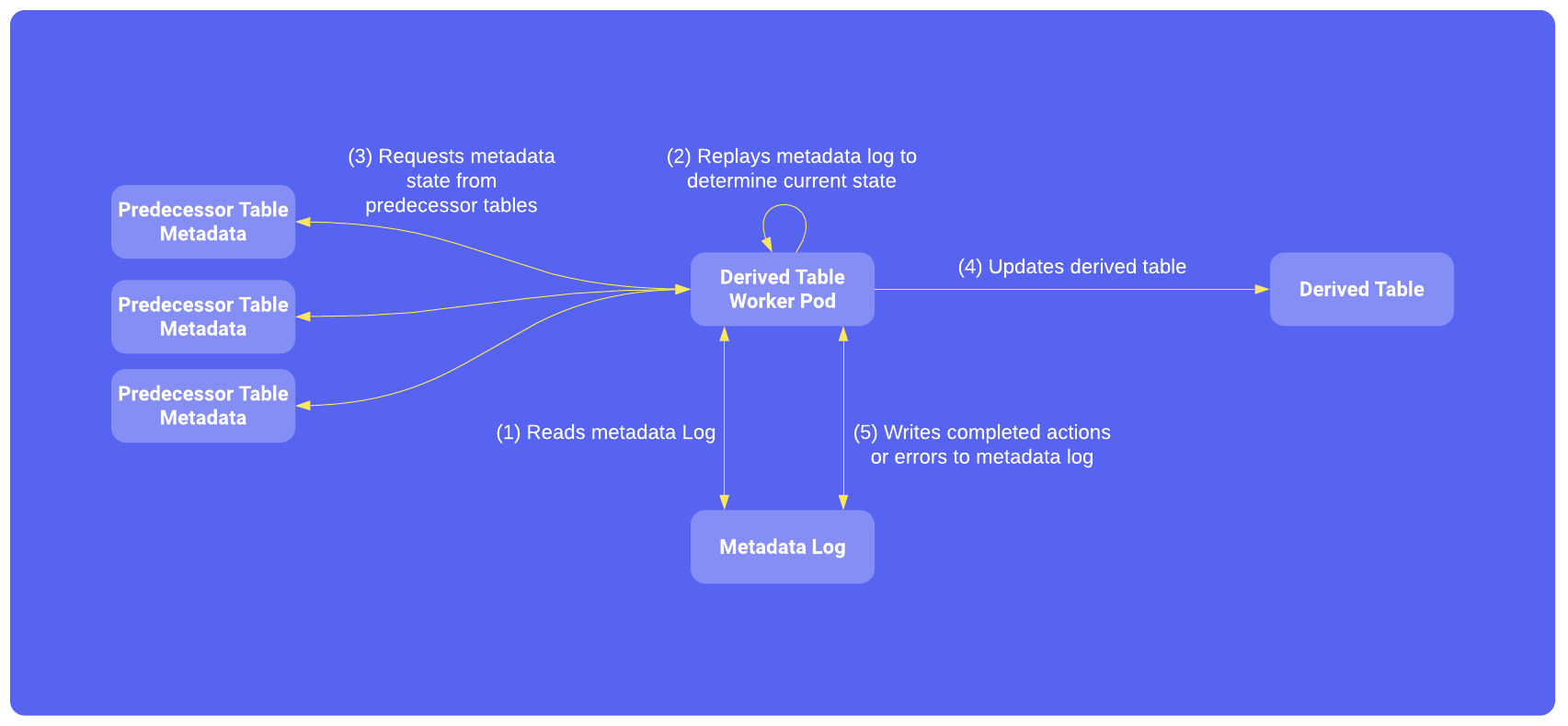
Le journal des métadonnées est disponible dans BigQuery et permet une surveillance détaillée, une analyse des performances et une lignée de données. Il répond à des questions de surveillance telles que Quand la table a-t-elle été mise à jour pour la dernière fois ? Les données de la table sont-elles récentes ? Pour l'analyse des performances, nous joignons le journal des métadonnées au fichier information_schema de BigQuery pour obtenir des détails sur l'exécution des requêtes et pour établir des rapports sur les métriques de chaque table. La lignée des données peut être obtenue à partir du journal des métadonnées en suivant les dépendances des prédécesseurs lorsque les tables sont mises à jour, de sorte que la lignée entière puisse être reconstruite en parcourant le journal des métadonnées.
Fonctionnalités de Discord :
Jusqu'à présent, Derived ne fonctionnait que sur des jeux de données BigQuery (un entrepôt de données conçu pour le traitement du Big Data) qui ont souvent des temps de réponse aux requêtes supérieurs à une seconde. Afin d'alimenter les fonctionnalités de l'application, les temps de réponse devaient être beaucoup plus rapides, en particulier pour les fonctionnalités d'apprentissage automatique où le flux de l'application est le suivant : recevoir une demande de l'utilisateur, interroger plusieurs jeux de données de Derived pour créer un ensemble de caractéristiques, faire une prédiction et répondre à l'utilisateur en une seconde. Pour cela, nous avons ajouté une nouvelle option de configuration sur Derived pour exporter automatiquement de BigQuery vers Scylla afin que le jeu de données de Derived soit disponible dans une base de données conçue pour les requêtes de haute performance dans les systèmes en ligne.
Conclusion
Nous utilisons la version 3 en production depuis plus d'un an maintenant et nous avons atteint les sept objectifs initiaux que nous nous étions fixés...
✔️ Les mises à jour de tables devraient s'effectuer aussitôt que les données sont disponibles (mais pas avant) !
✔️ Maintenir une piste d'audit des mutations vers les ensembles de données dérivées.
✔️ Les primitives sont incluses pour alimenter les outils de lignée et de catalogue de données.
✔️ Les modifications du DAG doivent être en libre-service et intuitives pour les équipes des parties prenantes comme l'ingénierie, la science des données et l'apprentissage automatique.
✔️ Connaissance des contrôles d'accès aux données et application évolutive des politiques de gouvernance des données.
✔️ Capable d'exporter automatiquement des données dérivées vers des banques de données de production pour les utiliser dans le produit de Discord destiné aux utilisateurs.
✔️ Simplicité et facilité d'utilisation dans le contexte de l'environnement de Discord.
... mais le voyage est loin d'être terminé, il y a maintenant des milliers de tables en production et l'équipe reçoit souvent des commentaires et des suggestions de personnes engagées en interne qui utilisent Derived pour construire des ensembles de données très complexes. Le système traite quotidiennement des pétaoctets de données provenant d'une multitude de points de données et nous améliorons toujours plus les performances et les fonctionnalités de Derived. Nous travaillons actuellement sur une version 4 - nous sommes très créatifs avec les noms de nos projets - et nous sommes impatients de partager nos connaissances sur les itérations à venir.
Ouf ! C'était beaucoup d'informations et toute une aventure pour l'équipe ! Si travailler avec des données massives vous intéresse, nous vous invitons à consulter notre page d'offres d'emploi et à postuler !